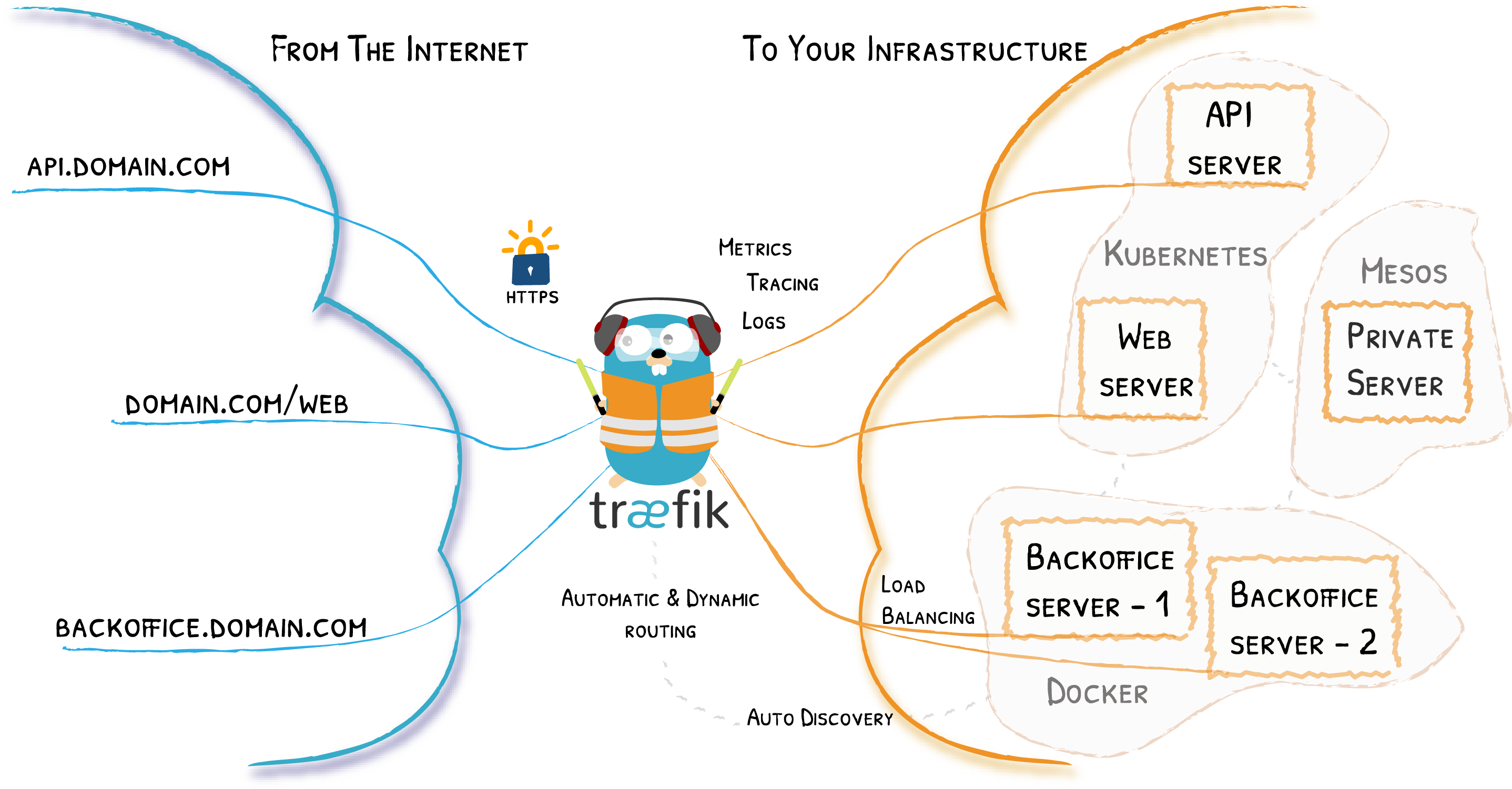
Alo7 分享. 解释规范中的内容, 以为为什么要这样做.(写的总比说的少)
索引数据结构(放到最后防止开篇劝退.)
SQL 调优
为什么要有索引:以 JOIN Algorithms 为例
假设存在表: School(id int, name char) 和 Clazz(id int, school_id int refer School)
sql:
select *
from
school
inner join
clazz
on school_id = school.id
where name > 'a'
以上 SQL在各个算法下的实现
Nested-Loop Join Algorithm
伪代码:
for each row in School matching range {
for each row in Clazz [matching reference key] {
if row satisfies join conditions, send to client
}
}
-
没有 index 的情况下: 复杂度 n^2
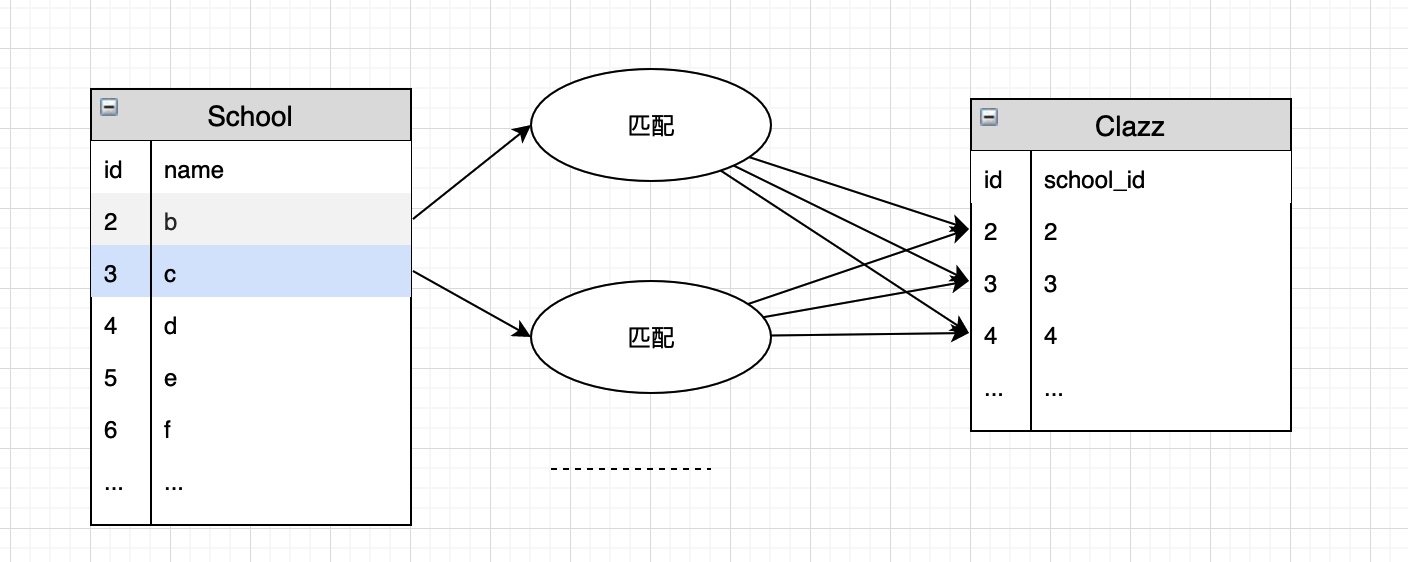
-
存在 index 的情况下: 复杂度 nlog(n)
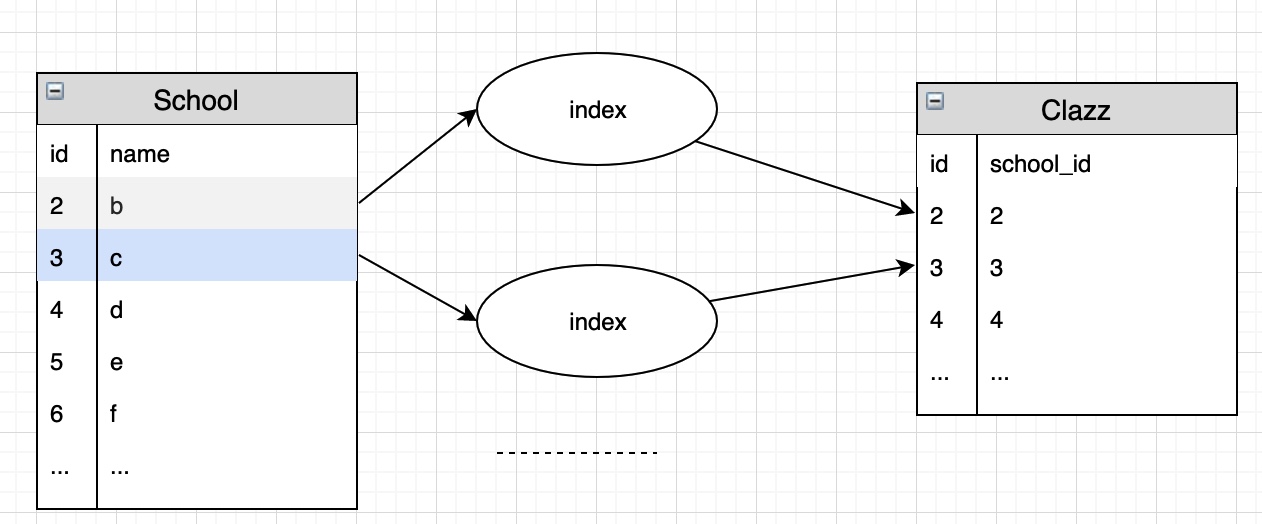
Block Nested-Loop Join Algorithm
伪代码:
for each row in School matching range {
store used columns from School in join buffer
if buffer is full {
for each row in Clazz {
for each School combination in join buffer {
if row satisfies join conditions, send to client
}
}
empty join buffer
}
}
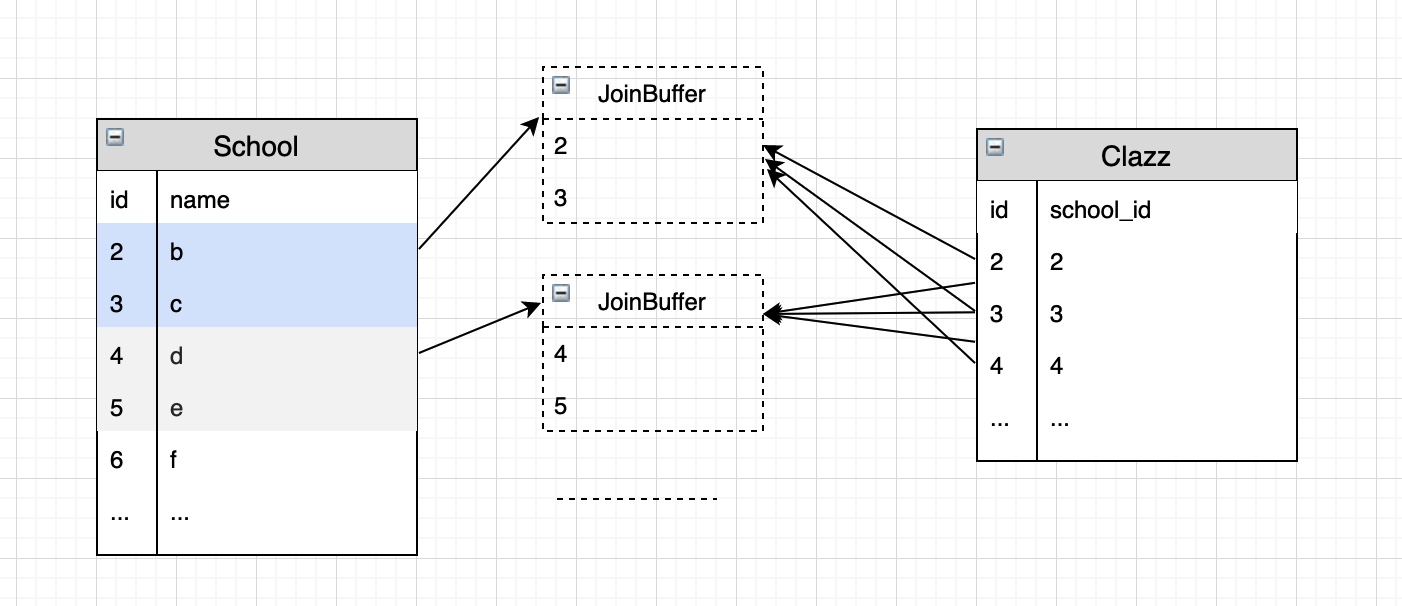 减少循环次数为:
减少循环次数为:s(单次存储大小) * c(存储次数) / JoinBufferSize + 1
所以:
JOIN 字段必须有索引 | JOIN 字段必须有索引 | JOIN 字段必须有索引以及不要进行太多表 join (阿里规范不超过 3 张)
基本原则: 最左匹配(5.7 及其以下版本)
假设存在表:t1(id int, key1 int, key2 int, key3 int, nokey int) idx_comb(k1, k2, k3)
索引idx_comb的存在相当于建立如下三个索引: idx(k1), idx(k1, k2) 和 idx(k1, k2, k3)
意味着如下查询能使用索引:
select * from t1 where c(k1);
select * from t1 where c(k1, k2);
select * from t1 where c(k1, k2, k3);
但是如下查询不行:
select * from t1 where c(k2);
select * from t1 where c(k2, k3);
所以:
避免创建冗余索引
优化三个工具: EXPLAIN, PROFILE, OPTIMIZER_TRACE
网上文档提别多这里不细讲, 会在后面使用的时候介绍
Explain:
- 用处: 查看一个这些SQL语句的执行计划。 比如有没有使用索引, 使用那些索引等等。
- 使用:
explain [extended | format=json] sql; [show warnings;]
PROFILE
- 用处: 查询SQL
实际执行状态, 如 System lock、Table lock 和排序 花多少时间等等 - 使用:
SET profiling = 1; sql SHOW PROFILES; SHOW PROFILE FOR QUERY <QueryID>
OPTIMIZER_TRACE
- 使用:查
实际执行流程,分析、验证优化思路SET OPTIMIZER_TRACE="enabled=on"; SET OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000; sql SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
Query Optimizer Hints:
- SQL_NO_CACHE: 不使用缓存(另外从 mysql 8 起不再支持 query cache)
- SQL_BUFFER_RESULT: 强制将结果先缓存至临时表, 再返回客户端.(在将大量数据发送至客户端时尽可能快的释放表锁)
range(以下均适用于btree, hash 限制略有不同):
mysql中所有的条件最终都会被优化为range, 等值是range的一种特列.
比如: a=2 会被解析为 2 <= a <= 2
Range Access Method for Single/Many-Part Indexes:
限制:
- 几乎支持所有操作符, 其中like要求不以统配符作为起始字符, 即: 符合
like 'abc%'不符合like '%bc%' - 操作符两侧为index key(满足最左匹配) 和 常量
- 常量包括: [str, 来自 const(只查出一行) join, 来自 system(表只有一行) join, 非相关子查询]
估算索引扫描范围: 存在以下sql:
-- keyword 有索引, ename 没有索引
SELECT
keyword
FROM
course
WHERE
(keyword < 'DZ' AND (keyword LIKE 'DQ%' OR keyword LIKE '%English' ))
OR
(keyword < 'Alo7' AND keyword IS NOT NULL AND ename = 'ABC Books Video')
OR
(keyword < 'u' AND keyword > 'z')
通过OPTIMIZER_TRACE得到条件优化结果:
// 最终优化为: "NULL < keyword < DZ"
{
"range_scan_alternatives": [
{
"index": "index_course_on_keyword",
"ranges": [
"NULL < keyword < DZ"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 225,
"cost": 271.01,
"chosen": false,
"cause": "cost"
}
]
}
咱们来推导以下这个range 条件怎么得到的:
-- 原始条件:
(keyword < 'DZ' AND (keyword LIKE 'DQ%' OR keyword LIKE '%English' ))
OR
(keyword < 'Alo7' AND keyword IS NOT NULL AND ename = 'ABC Books Video')
OR
(keyword < 'u' AND keyword > 'z')
-- 用TRUE替换非range 条件.
(keyword < 'DZ' AND (keyword LIKE 'DQ%' OR TRUE ))
OR
(keyword < 'Alo7' AND keyword IS NOT NULL AND TRUE)
OR
(keyword < 'u' AND keyword > 'z')
-- 简化/折叠 条件
--- 1. 评估并简化含TRUE/FALSE 表达式
(keyword < 'DZ' AND TRUE)
OR
(keyword < 'Alo7' AND keyword IS NOT NULL AND TRUE)
OR
(FALSE)
--- 2. 删除非必要TRUE/FALSE
(keyword < 'DZ')
OR
(keyword < 'Alo7' )
-- 合并条件
(keyword < 'DZ')
再举个例子: 存在如下两个sql:
select count(*)
from room m
where
m.scheduled_time <= '2019-09-16 21:10:41.775'
and DATE_ADD(m.scheduled_time, INTERVAL m.scheduled_duration + 15 MINUTE) > '2019-09-16 21:10:41.775' ;
-- expalin 结果
# id, select_type, table, partitions, type, key, key_len,ref, rows, filtered, Extra
# 1, SIMPLE, m, , range, idx_on_room_scheduled_time_and_expected_end_time, 5, , 3157, 100.00, Using index condition; Using where
select count(*)
from room m
where
m.scheduled_time <= '2018-09-16 21:10:41.775'
and m.scheduled_time > DATE_ADD('2018-09-16 21:10:41.775', INTERVAL -(50 + 15) MINUTE) ;
-- expalin 结果
# id, select_type, table, partitions, type, key, key_len, ref, rows, filtered, Extra
# 1, SIMPLE, m, , range, idx_on_room_scheduled_time_and_expected_end_time, 5, , 3 , 100.00, Using where; Using index
-- 问题: 两个SQL都是用了 idx_on_room_scheduled_time_and_expected_end_time 索引, 而且 使用索引长度均为: key_len 但是 评估rows缺相差许多(3157 : 3)
-- 原因: 前者range范围为: m.scheduled_time <= '2018-09-16 21:10:41.775'
-- 后者range范围为: DATE_ADD('2018-09-16 21:10:41.775', INTERVAL -(50 + 15) MINUTE) < m.scheduled_time <= '2018-09-16 21:10:41.775'
-- 另外: 第一个语句explain中的 Using index condition 说明他用到了 Index Condition Pushdown(ICP) 优化.
针对第一个sql可能的优化方案如下:
- 如果我们能在(model层)配置中得到
scheduled_duration的最大值那就能极快的改写成第二个语句; - 使用虚拟列(虚拟列最后介绍)
- 改写成如下的语句并补充scheduled_duration索引来达到同样效果
select SQL_NO_CACHE *
from room m
where
m.scheduled_time <= '2018-09-16 21:10:41.775'
and m.scheduled_time > DATE_ADD(
'2018-09-16 21:10:41.775' ,
INTERVAL - (select max(scheduled_duration) from room) - 15 MINUTE)
-- 在scheduled_duration存在索引的情况下 explain 会如下表示:
-- id, select_type, table, type, key, key_len, ref, rows, filtered, Extra
-- 1 PRIMARY m range idx_on_room_scheduled_time_and_expected_end_time 5 3 100.00 Using index condition; Using where
-- 2 SUBQUERY Select tables optimized away
-- 其中Select tables optimized away 表示读一次索引即可得到结果(min, max 等聚合函数优化)
反正
不要对索引列使用函数不要对索引列使用函数不要对索引列使用函数
Many-Valued Comparisons: index drive, index statistics
- index drive: 依据索引进行精确评估
- index statistics: 依据统计信息进行粗略评估
- 两个参数受: eq_range_index_dive_limit 变量影响。
存在如下数据:
-- 存在如下索引
show index in exercise_answers;
/*
exercise_answers 0 PRIMARY 1 id A 1125424848 BTREE
exercise_answers 1 index_exercise_answers_on_passport_id_and_exercise_id 1 passport_id A 7604221 YES BTREE
exercise_answers 1 index_exercise_answers_on_passport_id_and_exercise_id 2 exercise_id A 1125424848 YES BTREE
exercise_answers 1 index_exercise_answers_on_owner_type_and_owner_id 1 owner_type A 3390 YES BTREE
exercise_answers 1 index_exercise_answers_on_owner_type_and_owner_id 2 owner_id A 112542484 YES BTREE
*/
-- 第一组索引数据个数
select count(*) from exercise_answers
where passport_id = '99987175' and exercise_id in (460240,460241,460242,460243,460244,460245,460246,460247,460248,460249,460250,460251,460252,460253,460254,460255,460256,460257,460258,460261,460262,460263,460264,460266,460267,460268,460269,460270,460271,460272,460273,460274,460275,460276,460277,460278,460279,460280,460281,460282,460283,460284,460285,460286,460287,460288,460294,460295,460296,460297,460298,460329,460330,460331,460332,460333,460334,460335,460336,460337,460338,460339,460340,460341,460342,460343,460344,460345,460346,460347,460348,460349,460350,460351,460352,460353,460354,460355,460356,460357,460358,460359,460360,460361,460362,460363,460364,460365,460366,460367,460368,460369,460370,460371,460372,460389,460390,460391,460392,460393,460395,460396,460397,460398,460399,460404,460405,460406,460407,460408,460409,460410,460411,460412,460413,460416,460417,460418,460419,460420,460421,460422,460423,460424,460425,460426,460427,460428,460429,460430,460431,460432,460433,460434,460435,460444,460445,460446,460447,460448,460449,460450,460451,460452,460453,460454);
-- > 200
-- 第二组索引数据个数
select count(*) from exercise_answers
where owner_type='Homework' and owner_id in (3199716,2471583);
-- > 1157
-- 评估如下查询:使用哪个索引?
select sql_no_cache count(*) c from exercise_answers
where passport_id = '99987175' and owner_type='Homework'
and exercise_id in (460240,460241,460242,460243,460244,460245,460246,460247,460248,460249,460250,460251,460252,460253,460254,460255,460256,460257,460258,460261,460262,460263,460264,460266,460267,460268,460269,460270,460271,460272,460273,460274,460275,460276,460277,460278,460279,460280,460281,460282,460283,460284,460285,460286,460287,460288,460294,460295,460296,460297,460298,460329,460330,460331,460332,460333,460334,460335,460336,460337,460338,460339,460340,460341,460342,460343,460344,460345,460346,460347,460348,460349,460350,460351,460352,460353,460354,460355,460356,460357,460358,460359,460360,460361,460362,460363,460364,460365,460366,460367,460368,460369,460370,460371,460372,460389,460390,460391,460392,460393,460395,460396,460397,460398,460399,460404,460405,460406,460407,460408,460409,460410,460411,460412,460413,460416,460417,460418,460419,460420,460421,460422,460423,460424,460425,460426,460427,460428,460429,460430,460431,460432,460433,460434,460435,460444,460445,460446,460447,460448,460449,460450,460451,460452,460453,460454)
and owner_id in (3199716,2471583)
Explain 对比:
-- 使用 index stat
set eq_range_index_dive_limit=1;
-- explain 结果(请注意使用的 index)
/*
{
"query_block": {
"select_id": 1,
"table": {
"table_name": "exercise_answers",
"access_type": "range",
"possible_keys": [
"index_exercise_answers_on_passport_id_and_exercise_id",
"index_exercise_answers_on_owner_type_and_owner_id"
],
"key": "index_exercise_answers_on_owner_type_and_owner_id",
"used_key_parts": [
"owner_type",
"owner_id"
],
"key_length": "773",
"rows": 20,
"filtered": 75,
"index_condition": "((`saybot_vw`.`exercise_answers`.`owner_type` = 'Homework') and (`saybot_vw`.`exercise_answers`.`owner_id` in (3199716,2471583)))",
"attached_condition": "((`saybot_vw`.`exercise_answers`.`passport_id` = '99987175') and (`saybot_vw`.`exercise_answers`.`exercise_id` in (460240,460241,460242,460243,460244,460245,460246,460247,460248,460249,460250,460251,460252,460253,460254,460255,460256,460257,460258,460261,460262,460263,460264,460266,460267,460268,460269,460270,460271,460272,460273,460274,460275,460276,460277,460278,460279,460280,460281,460282,460283,460284,460285,460286,460287,460288,460294,460295,460296,460297,460298,460329,460330,460331,460332,460333,460334,460335,460336,460337,460338,460339,460340,460341,460342,460343,460344,460345,460346,460347,460348,460349,460350,460351,460352,460353,460354,460355,460356,460357,460358,460359,460360,460361,460362,460363,460364,460365,460366,460367,460368,460369,460370,460371,460372,460389,460390,460391,460392,460393,460395,460396,460397,460398,460399,460404,460405,460406,460407,460408,460409,460410,460411,460412,460413,460416,460417,460418,460419,460420,460421,460422,460423,460424,460425,460426,460427,460428,460429,460430,460431,460432,460433,460434,460435,460444,460445,460446,460447,460448,460449,460450,460451,460452,460453,460454)))"
}
}
}*/
-- 使用 index dive
set eq_range_index_dive_limit=3;
-- explain 结果
/*
{
"query_block": {
"select_id": 1,
"table": {
"table_name": "exercise_answers",
"access_type": "range",
"possible_keys": [
"index_exercise_answers_on_passport_id_and_exercise_id",
"index_exercise_answers_on_owner_type_and_owner_id"
],
"key": "index_exercise_answers_on_passport_id_and_exercise_id",
"used_key_parts": [
"passport_id",
"exercise_id"
],
"key_length": "773",
"rows": 200,
"filtered": 100,
"index_condition": "((`saybot_vw`.`exercise_answers`.`passport_id` = '99987175') and (`saybot_vw`.`exercise_answers`.`exercise_id` in (460240,460241,460242,460243,460244,460245,460246,460247,460248,460249,460250,460251,460252,460253,460254,460255,460256,460257,460258,460261,460262,460263,460264,460266,460267,460268,460269,460270,460271,460272,460273,460274,460275,460276,460277,460278,460279,460280,460281,460282,460283,460284,460285,460286,460287,460288,460294,460295,460296,460297,460298,460329,460330,460331,460332,460333,460334,460335,460336,460337,460338,460339,460340,460341,460342,460343,460344,460345,460346,460347,460348,460349,460350,460351,460352,460353,460354,460355,460356,460357,460358,460359,460360,460361,460362,460363,460364,460365,460366,460367,460368,460369,460370,460371,460372,460389,460390,460391,460392,460393,460395,460396,460397,460398,460399,460404,460405,460406,460407,460408,460409,460410,460411,460412,460413,460416,460417,460418,460419,460420,460421,460422,460423,460424,460425,460426,460427,460428,460429,460430,460431,460432,460433,460434,460435,460444,460445,460446,460447,460448,460449,460450,460451,460452,460453,460454)))",
"using_MRR": true,
"attached_condition": "((`saybot_vw`.`exercise_answers`.`owner_type` = 'Homework') and (`saybot_vw`.`exercise_answers`.`owner_id` in (3199716,2471583)))"
}
}
}
*/
Profiling 对比:
| status | index dive | index stat | 备注 |
|---|---|---|---|
| Sending data | 0.000825 | 0.002600 | stat 处理了更多的数据 |
| statistics | 0.000231 | 0.000127 | stat 分析时间更短 |
OPTIMIZER_TRACE:
//use index stat
{
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "index_exercise_answers_on_passport_id_and_exercise_id",
"ranges": [
"99987175 <= passport_id <= 99987175 AND 460240 <= exercise_id <= 460240",
"99987175 <= passport_id <= 99987175 AND 460241 <= exercise_id <= 460241",
"......",
"99987175 <= passport_id <= 99987175 AND 460454 <= exercise_id <= 460454"
],
"index_dives_for_eq_ranges": false, // do not use dive
"rowid_ordered": false,
"using_mrr": true,
"index_only": false,
"rows": 146,
"cost": 199.88,
"chosen": true
},
{
"index": "index_exercise_answers_on_owner_type_and_owner_id",
"ranges": [
"Homework <= owner_type <= Homework AND 2471583 <= owner_id <= 2471583",
"Homework <= owner_type <= Homework AND 3199716 <= owner_id <= 3199716"
],
"index_dives_for_eq_ranges": false,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 20,
"cost": 26.01, //cost 26 < 199
"chosen": true
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
// use index dive; eq_range_index_dive_limit=3
{
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "index_exercise_answers_on_passport_id_and_exercise_id",
"ranges": [
"99987175 <= passport_id <= 99987175 AND 460240 <= exercise_id <= 460240",
"99987175 <= passport_id <= 99987175 AND 460241 <= exercise_id <= 460241",
"......",
"99987175 <= passport_id <= 99987175 AND 460454 <= exercise_id <= 460454"
],
"index_dives_for_eq_ranges": false, // not use
"rowid_ordered": false,
"using_mrr": true,
"index_only": false,
"rows": 146,
"cost": 199.88,
"chosen": true
},
{
"index": "index_exercise_answers_on_owner_type_and_owner_id",
"ranges": [
"Homework <= owner_type <= Homework AND 2471583 <= owner_id <= 2471583",
"Homework <= owner_type <= Homework AND 3199716 <= owner_id <= 3199716"
],
"index_dives_for_eq_ranges": true, // use
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1155,
"cost": 1388, // 1388 > 199
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
// use index dive; eq_range_index_dive_limit=300
{
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "index_exercise_answers_on_passport_id_and_exercise_id",
"ranges": [
"99987175 <= passport_id <= 99987175 AND 460240 <= exercise_id <= 460240",
"......",
"99987175 <= passport_id <= 99987175 AND 460454 <= exercise_id <= 460454"
],
"index_dives_for_eq_ranges": true, // use
"rowid_ordered": false,
"using_mrr": true,
"index_only": false,
"rows": 200, // rows 变得准确
"cost": 274.38,
"chosen": true
},
{
"index": "index_exercise_answers_on_owner_type_and_owner_id",
"ranges": [
"Homework <= owner_type <= Homework AND 2471583 <= owner_id <= 2471583",
"Homework <= owner_type <= Homework AND 3199716 <= owner_id <= 3199716"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1155,
"cost": 1388,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
所以:
注意 in 条件个数不要过多, 过多的in条件会使用 index stat 来生成执行计划, 如果数据分布不均, 会导致错误的选择Index
下面这些优化都是特例优化. 在设计时不应该过多考虑.
NULL 优化:
官方建议如果可能尽可能声明列为NOT NULL; 如果有需求使用NULL值, 请尽情使用. 文档地址
所以建议:
尽可能减少 NULL 列, NULL 会增加索引扫描和条件对比的复杂度
Index Merge:
在特定情况下一个表可以使用多个索引. 依次介绍每一种方式 couse表存在 idx(category_id), pk(id)
- Index Merge Intersection Access Algorithm: 对多个索引同时扫描并对结果取交集
select * from course where category_id = 10 and id < 10;
-- explain
# id, select_type, table, type, key, key_len, rows, Extra
# 1, SIMPLE, course, index_merge, category_id_idx,PRIMARY, 9,4, , 1, Using intersect(category_id_idx,PRIMARY); Using where
另外如果发生了这种优化, 建议使用复合索引. 具体参考文档
- Index Merge Union Access Algorithm: 对多个索引同时扫描并对结果取并集
select * from course where category_id = 10 or id < 10;
-- explain
# id, select_type, table, type, key, key_len, rows, Extra
# 1, SIMPLE, course, index_merge, category_id_idx,PRIMARY, 5,4, , 12, Using union(category_id_idx,PRIMARY); Using where
- Index Merge Sort-Union Access Algorithm 对多个索引同时扫描并对结果取并集
select * from course where category_id < 10 or id < 10;
-- explain
# id, select_type, table, type, key, key_len, rows, Extra
# 1, SIMPLE, course, index_merge, category_id_idx,PRIMARY, 5,4, , 12, Using union(category_id_idx,PRIMARY); Using where
-- 这个相比union: category_id < 10 只能使用到 category_id 这个一部分 , 而 category_id = 10 使用到 category_id, id 两个部分.
所以请仔细思考会进行range查询的列在索引中的位置
函数调用优化:
函数分为: 稳定(deterministic)非稳定(nondeterministic)两类函数. 非稳定函数会影响索引使用
select scheduled_time from room where scheduled_time > now() + INTERVAL 10 DAY;
-- explain
# id, select_type, table, type, key, key_len, ref, rows, filtered, Extra
# 1, SIMPLE, room, range, idx_on_room_scheduled_time_and_expected_end_time, 5, , 126263, 100.00, Using where; Using index
select scheduled_time from room where scheduled_time > now() + INTERVAL floor(rand()* 10) DAY;
# id, select_type, table, type, key, key_len, ref, rows, filtered, Extra
# 1, SIMPLE, room, index, idx_on_room_scheduled_time_and_expected_end_time, 10, , 252527, 33.33, Using where; Using index
-- 前者range 后者index
所以: 请注意 不稳定函数使用
子查询优化
| type | 优化类型 | 备注 |
|---|---|---|
| in/any | Semijoin | |
| Materialization | ||
| EXISTS strategy | ||
| not in | Materialization | |
| EXISTS strategy | ||
| derived table/views | Merge the derived table into the outer query block | 从5.7开始支持views的优化(下同) <br >5.6,5.7虽然都叫这个名字但是行为相差很大 |
| Materialize the derived table to an internal temporary table |
SemiJoin
简单说: 两张表关系为1:n, 结果只需要1中的内容, n中的内容仅仅用来过滤.
举个栗子: 问: 查询存在学生的班级?
SELECT SQL_NO_CACHE
count(DISTINCT clazz.id)
FROM
clazz
INNER JOIN
clazz_student ON clazz.id = clazz_id;
-- 平均耗时1s
稍稍优化下(5.7 及以下):
SELECT SQL_NO_CACHE
COUNT(id)
FROM
clazz c
WHERE
exists (SELECT
1
FROM
clazz_student
WHERE
clazz_id = c.id);
-- 平均耗时0.55s
由于 clazz 和 clazz_student 是 1:n 在优化下:
SELECT SQL_NO_CACHE
COUNT(id)
FROM
clazz c
WHERE
id IN (SELECT
clazz_id
FROM
clazz_student
WHERE
clazz_id = c.id)
;
-- 平均耗时0.45s (单个查询优化了 55%)
-- explain后看下show warnings
/* select#1 */
select
sql_no_cache count(`saybot_vw`.`c`.`id`) AS `COUNT(id)`
from
`saybot_vw`.`clazz` `c`
semi join // first match
(`saybot_vw`.`clazz_student`) // 子查询上拉
where (`saybot_vw`.`clazz_student`.`clazz_id` = `saybot_vw`.`c`.`id`)
子查询另外的策略:
-- looseScan
SELECT SQL_NO_CACHE
COUNT(id)
FROM
clazz_course cu
WHERE
clazz_id IN (SELECT
clazz_id
FROM
clazz_student
WHERE
clazz_id < 20);
/*
table, rows, extra
clazz_student, 1 , Using where; Using index; LooseScan
c, , 1, Using index
解释:
1. 遍历 cs 中每一组, 注意是组取到 cls_id
2. 去 cls 表取 数据.
与 firstmatch 的区别: 前者 是 cls 表为驱动表, 和改过程相反
*/
-- duplicate weedout
SELECT SQL_NO_CACHE
COUNT(id)
FROM
clazz c
WHERE
id IN (SELECT
clazz_id
FROM
clazz_student
WHERE
clazz_id = c.id and id < 100);
/*
table, rows, extra
clazz_student, 1 , Using where; Start temporary
c, , 1, Using index; End temporary
解释:
1. 创建临时表 T
2. 遍历 cls_stu 中没一行
3. 取到 C 中的记录
4. 临时表去重
*/
5.7 新特性
Generated Column
mysql> CREATE TABLE jemp (
-> c JSON,
-> g INT GENERATED ALWAYS AS (c->"$.id"),
-> INDEX i (g)
-> );
Query OK, 0 rows affected (0.28 sec)
mysql> INSERT INTO jemp (c) VALUES
> ('{"id": "1", "name": "Fred"}'), ('{"id": "2", "name": "Wilma"}'),
> ('{"id": "3", "name": "Barney"}'), ('{"id": "4", "name": "Betty"}');
Query OK, 4 rows affected (0.04 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> SELECT c->>"$.name" AS name
> FROM jemp WHERE g > 2;
+--------+
| name |
+--------+
| Barney |
| Betty |
+--------+
2 rows in set (0.00 sec)
mysql> EXPLAIN SELECT c->>"$.name" AS name
> FROM jemp WHERE g > 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: jemp
partitions: NULL
type: range
possible_keys: i
key: i
key_len: 5
ref: NULL
rows: 2
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
派生表(Derived Tables)
举个栗子:
SELECT *
FROM t1 JOIN (SELECT t2.f1 FROM t2) AS derived_t2 ON t1.f2=derived_t2.f1
WHERE t1.f1 > 0;
SELECT t1.*, t2.f1
FROM t1 JOIN t2 ON t1.f2=t2.f1
WHERE t1.f1 > 0;
禁用方式(在子查中使用):
- 聚合函数
- distinct
- Group By
- HAVING
- Limit
- UNION
- …..
索引
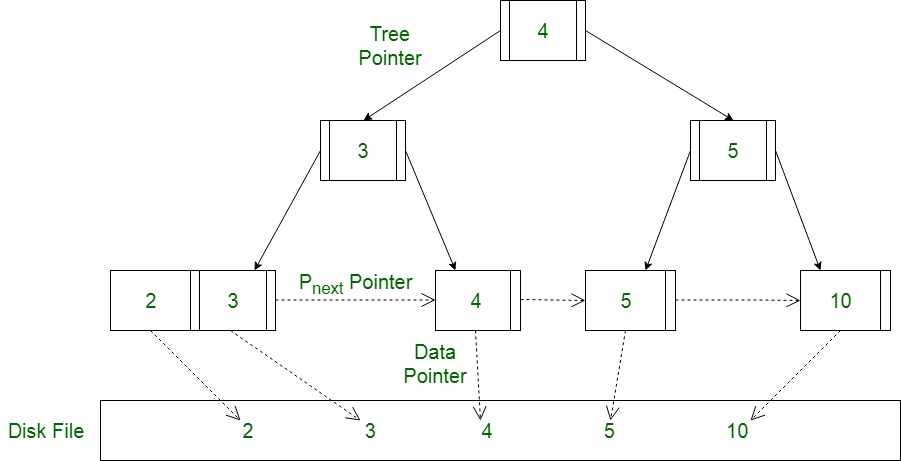
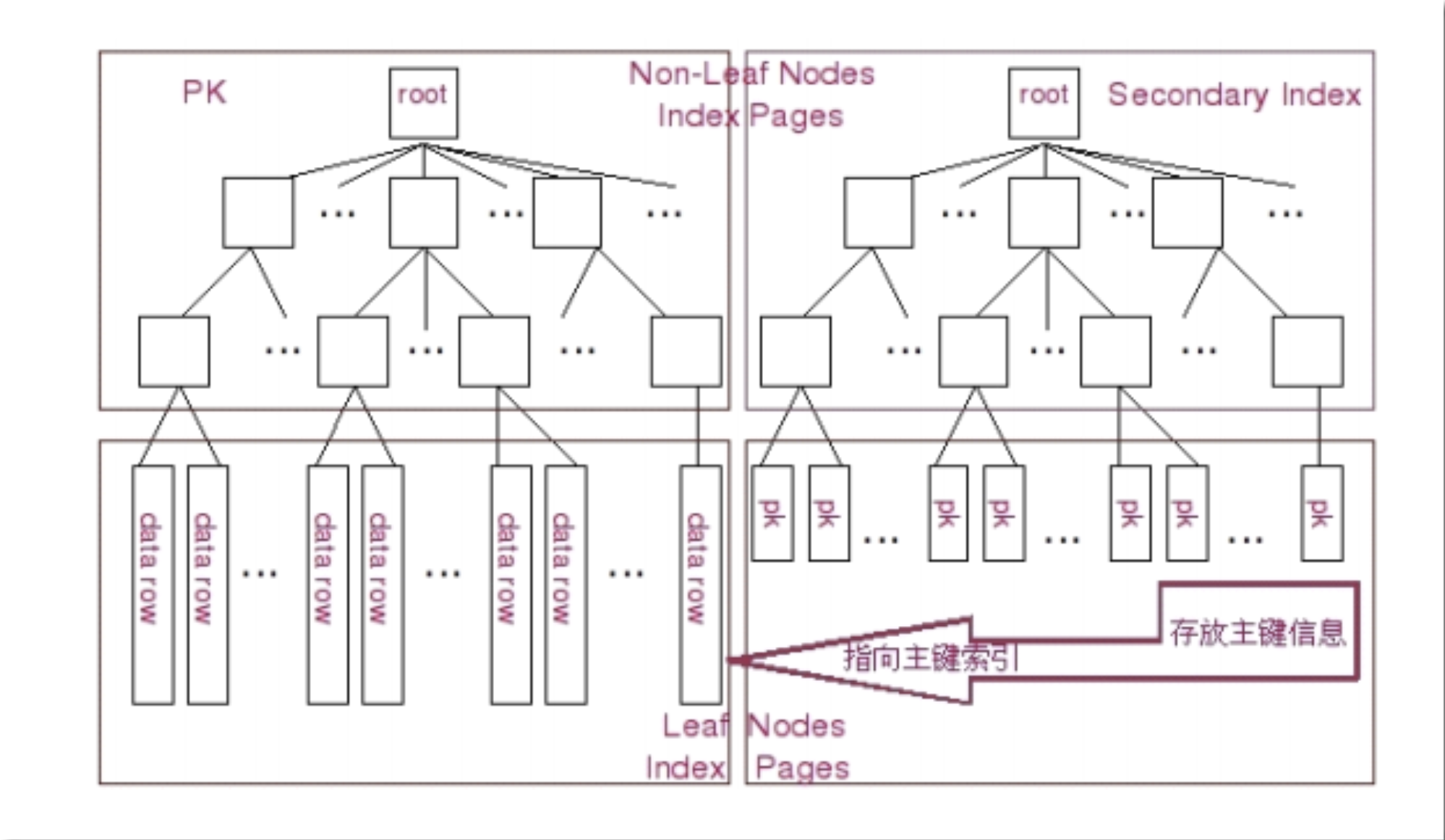
B+tree (以clustered index来讲)
图片依次盗自: 图1 图2
所以: 建议使用
自增列作为主键以减少索引分裂,重排的情况.
另外 innodb 默认一个 index page 为16kb. 以int为主键的列单page可以放入记录: 4k; 以bigint为主键可以放入记录 2k (实际单page只能使用容量的[1/2-5/6])
所以: 个人建议
能使用更小的数据类型就用更小的, 尤其是主键, 而且当主键设置为bigint的表应该在早期就设计分表(该条不在规范里)
Hash
图片依次盗自: 图1
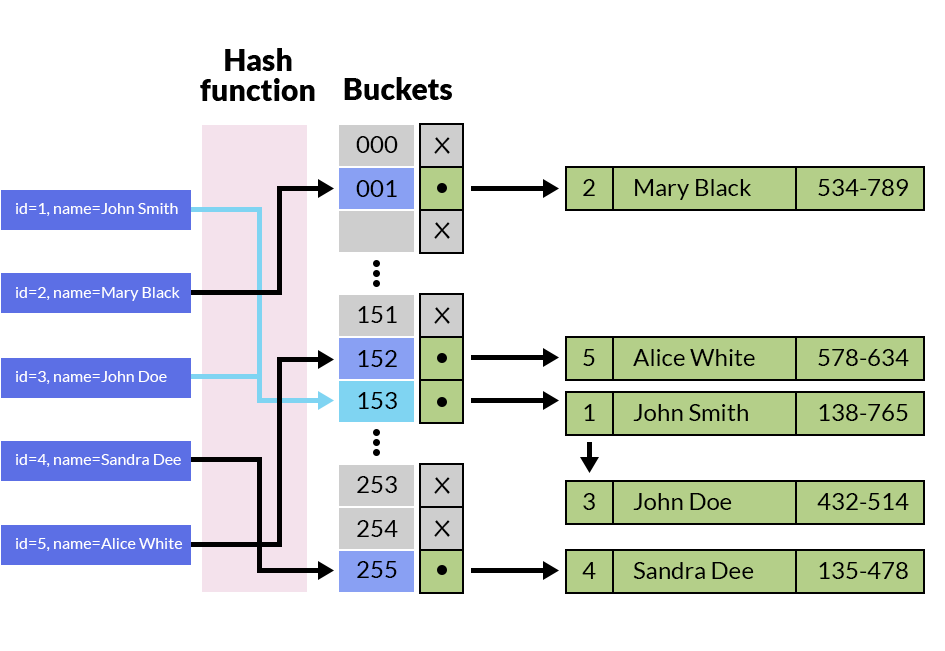
hash index 只能使用在memory engine(重启清空, 不支持事务, 只有表锁); hash index 擅长等值查询(=, <=>, …); btree 支持 range 查询(>, >=, bwteen…)
推荐:
未完成
其他
时区配置
字符编码
use index vs rs sorted key
group/order/distinct 优化:
group by
- order by null: sql 仅有 group by 语句时, 默认按照 groug by 字段顺序进行排序。 在很多情况下 并不需要这个行为。 order by null 可以忽略排序
explain
SELECT
clazz_id, student_id, count(*)
FROM
homeworks h
inner join
homework_results hr on hr.homework_id = h.id
where h.id > 3398853
group by clazz_id, student_id
limit 2000;
/*
# id, select_type, table, type, possible_keys, key, key_len, ref, rows, Extra
1, SIMPLE, hr, range, index_hw_id_and_hr_id,index_homework_results_on_homework_id, index_hw_id_and_hr_id, 5, , 883, Using where; Using index; Using temporary; Using filesort
1, SIMPLE, h, eq_ref, PRIMARY, PRIMARY, 4, saybot_vw.hr.homework_id, 1,
*/
-- >>> 0.053
explain
SELECT
clazz_id, student_id, count(*)
FROM
homeworks h
inner join
homework_results hr on hr.homework_id = h.id
where h.id > 3398853
group by clazz_id, student_id
order by null
limit 2000;
/*
# id, select_type, table, type, possible_keys, key, key_len, ref, rows, Extra
1, SIMPLE, hr, range, index_hw_id_and_hr_id,index_homework_results_on_homework_id, index_hw_id_and_hr_id, 5, , 883, Using where; Using index; Using temporary
1, SIMPLE, h, eq_ref, PRIMARY, PRIMARY, 4, saybot_vw.hr.homework_id, 1,
*/